

Many, many companies that are using SQL Server don’t have anyone on staff who really understands SQL Server. They often think of SQL Server as just the place where the data is stored and don’t understand how it should be configured or maintained. The teams at these companies are fantastic at what they do, but they just don’t have a DBA. Maybe they don’t even need one full time, but having someone like me on a part time basis can really help.
You may have seen that I give a presentation called the “Top 5 Mistakes You Are Probably Making with SQL Server.” I have finally decided that there is one mistake that outweighs the others: insufficient RAM.
In order for SQL Server to read and update data, the data must be in the buffer. SQL Server does not work directly with the data in the files on disk. Once the pages of data are in the buffer, they can be used for multiple queries. This means that the data doesn’t have to be retrieved from disk every time it’s needed, thereby decreasing the amount of I/O work required.
You may have seen this yourself when selecting all the rows of a large table twice. The second time, the query can run much faster because the data does not have to be copied from the disk to the buffer. If you run another query from a different large table, it may cause the pages from the first table to be removed to make room. If there is not enough memory, pages will have to be read from disk more frequently causing your queries to be slow.
When I have my first meeting with a new customer they tell me “Our application is slow. It’s been getting worse over time. We think the problem is with SQL Server, but we don’t know where to look.” One of the first things I check is how long the data pages can live in the buffer. I check this by looking at a performance counter called Page Life Expectancy or PLE. This is the number of seconds that a page is expected to last in memory. Unfortunately, the published value for this by Microsoft is 300. In today’s servers, the value should be much higher. I recently read a post from Jonathan Kehayias (@SQLPoolBoy) who said the minimum value should be 300 times the number of GB in the data cache divided by 4. To make it easier, just take the number of GB installed on the server or, if you have it configured properly, the max memory setting of the instance. Obviously, both of those number will be higher than the data cache size, but close enough. If you have multiple instances on a server, those instances will have to share the RAM, so keep that in mind as well.
I like to review the PLE values in a graph to see what is happening over time. (Take a look at this article by Linchpin People partner Mike Walsh (@mike_walsh) for an easy way to collect the data and create the graph by using the PAL tool.) If I see the PLE bottoming out or zigzagging during production hours, I know there is a problem with insufficient RAM. Occasional dips below the value calculated in the previous paragraph are fine, but we don’t want PLE to stay there. Here is an actual graph from a customer generated by using PAL on a server with 16 GB of RAM over an eight hour period.
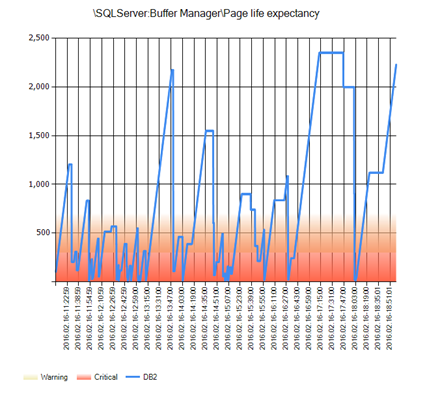
How can this problem be solved? There are really two aspects to the solution. The first is usually easy: increase the RAM. By having adequate RAM on the server, the data pages can live in the buffer longer and decrease I/O requirements. Performance can improve immediately.
The second part of the solution is more difficult and sometimes not possible: query and index tuning. By optimizing indexes and queries, a smaller number of pages are required by queries. This decreases both I/O and memory requirements.
The next time you hear someone complaining about how much memory SQL Server needs, just remember that memory is like air to SQL Server.




Very insightful post! “SQL Server does not work directly with the data in the files on disk. Once the pages of data are in the buffer, they can be used for multiple queries.” This quote alone really did a lot to change my perception of how things work. I didn’t even know that I was understanding things incorrectly (or in such a limited way).
I’m new to SQL – still absorbing lots of theoretical information about it and doing mock SQL work (https://github.com/MahoganyB/dataProjects/blob/master/SQLite3/Learning_with_SQLite3_1.ipynb). So finding your blog was really helpful Kathi. Thanks so much for sharing your expertise and insights in this way. It’s not only useful for professionals already working in the field (I’m sure), but it’s also really very useful for us learners too. Thank you.
Very insightful post! “SQL Server does not work directly with the data in the files on disk. Once the pages of data are in the buffer, they can be used for multiple queries.” This quote alone really did a lot to change my perception of how things work. I didn’t even know that I was understanding things incorrectly (or in such a limited way).
I’m new to SQL – still absorbing lots of theoretical information about it and doing mock SQL work (https://github.com/MahoganyB/dataProjects/blob/master/SQLite3/Learning_with_SQLite3_1.ipynb). So finding your blog was really helpful Kathi. Thanks so much for sharing your expertise and insights in this way. It’s not only useful for professionals already working in the field (I’m sure), but it’s also really very useful for us learners too. Thank you.
I’m so glad you found this helpful. It is definitely a common issue. Good luck in your learning.
Kathi